Avant de déployer le moindre modèle d'IA, les organisations doivent résoudre une question plus fondamentale : peuvent-elles faire confiance à leurs données ? La gouvernance n'est pas un prérequis administratif, c'est une décision stratégique.
Nous vivons à une époque où les budgets IA des entreprises n'ont jamais été aussi élevés. Selon Gartner, plus de 80 % des entreprises prévoient d'intensifier leurs investissements en intelligence artificielle d'ici fin 2026. Pourtant, une proportion alarmante de projets estimée entre 60 et 85 % selon les études ne parviennent pas à générer la valeur attendue.
La cause principale ? Rarement la technologie. Presque toujours : la donnée.
Des données incomplètes, dupliquées, mal étiquetées ou sans propriétaire clairement identifié rendent les modèles les plus sophistiqués inefficaces. Un algorithme d'IA est aussi fiable que le carburant qu'on lui fournit. Si ce carburant est pollué, la machine produit du bruit pas de la valeur.
C'est là que la gouvernance des données entre en jeu. Non pas comme un projet informatique supplémentaire à inscrire au backlog, mais comme la condition de réussite de toute stratégie data et IA durable.
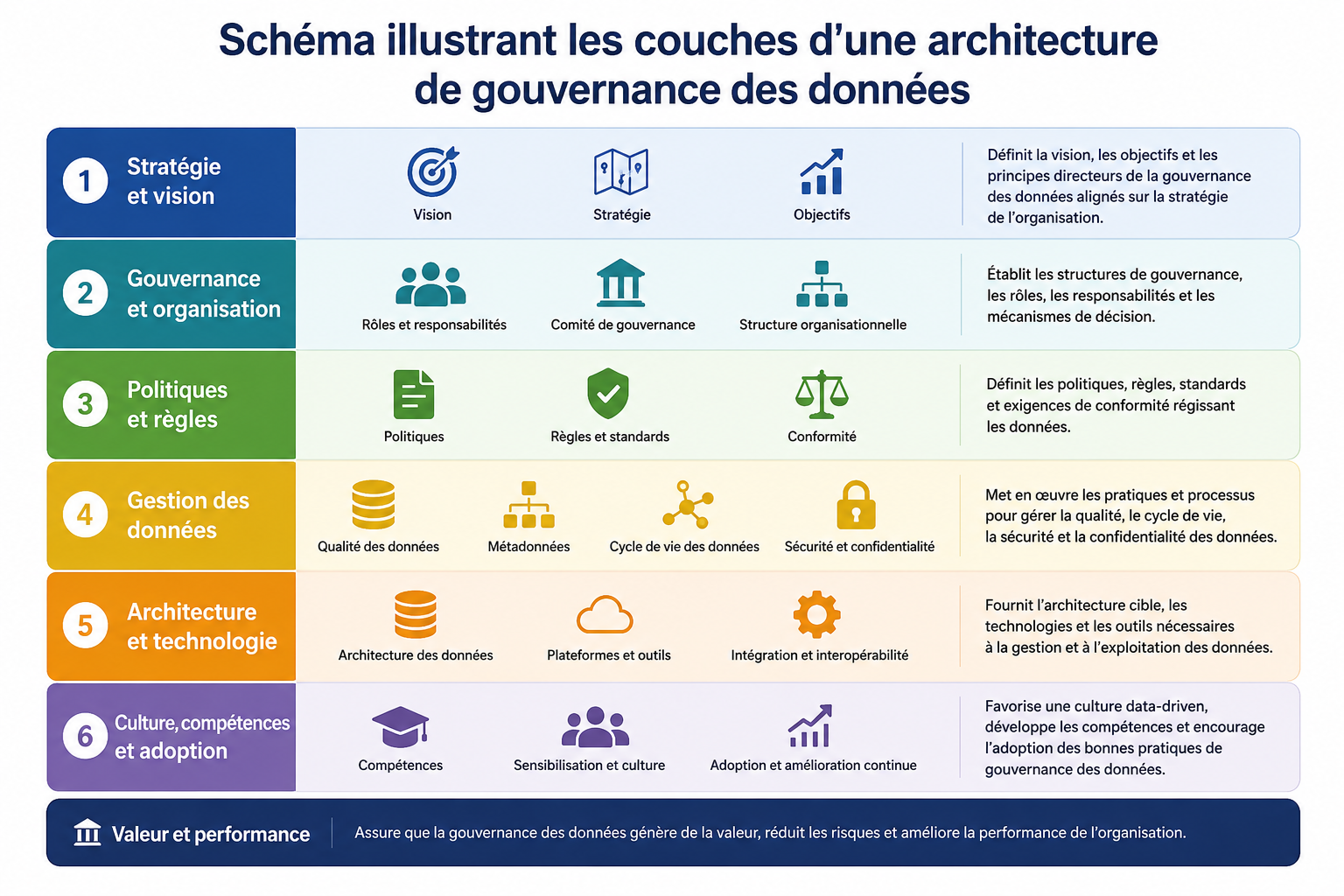
Illustration : Architecture de gouvernance des données de la collecte à la décision
Qu'entend-on réellement par gouvernance des données ?
Le terme est souvent mal compris, parfois réduit à une politique RGPD ou à un projet de Master Data Management (MDM). En réalité, la gouvernance des données désigne l'ensemble des règles, rôles, processus et standards qui définissent : qui peut faire quoi avec quelle donnée, dans quel cadre et pour quel usage.
Elle couvre trois dimensions indissociables :
1. La qualité des données
Une donnée de qualité est exacte, complète, cohérente, actuelle et accessible. Les organisations qui ne mesurent pas la qualité de leurs données naviguent à vue et le découvrent souvent lors du lancement d'un projet analytique ou d'un déploiement IA. Le coût des données de mauvaise qualité est estimé par IBM à 3,1 billions de dollars annuels pour l'économie américaine seule.
2. Le catalogage et la traçabilité (Data Lineage)
Savoir où une donnée a été créée, comment elle a été transformée, qui l'a modifiée et à quel moment, c'est la traçabilité. Sans elle, il est impossible d'auditer un modèle IA, de corriger une anomalie ou de répondre aux exigences réglementaires. Des outils comme Microsoft Purview ou Alation permettent de construire ce catalogue vivant.
3. Les rôles et responsabilités (Data Ownership)
Chaque donnée doit avoir un propriétaire métier identifié pas seulement technique. Ce "Data Owner" est responsable de la pertinence, de la mise à jour et de l'usage de ses données. Sans ce principe, les données deviennent orphelines : personne ne les maintient, tout le monde les utilise.
En résumé : la gouvernance des données n'est pas un projet IT, c'est un programme de transformation organisationnelle qui implique les métiers autant que la DSI. Elle définit les règles du jeu de toute stratégie data.
Pourquoi c'est le chantier prioritaire avant l'IA
La corrélation est directe : les organisations qui obtiennent les meilleurs résultats avec l'IA sont celles qui ont, en amont, investi dans la structuration de leur patrimoine de données. Ce n'est pas une coïncidence.
Prenons un exemple concret. Une entreprise souhaite déployer un modèle prédictif pour anticiper le churn client. Elle dispose de données dans son CRM, son ERP, son outil de support et ses logs d'usage. Mais ces sources ne sont pas alignées : les identifiants clients diffèrent d'un système à l'autre, les dates de dernière interaction sont renseignées de façon incohérente, et certaines colonnes critiques contiennent 40 % de valeurs nulles.
Résultat : 70 % du temps du projet est absorbé par la préparation et la correction des données. Le modèle est livré avec 6 mois de retard, sur une base fragile. Et si les données sources changent, tout est à refaire.
"Les données sont le pétrole de l'IA. Mais du pétrole brut non raffiné ne fait pas tourner un moteur."
Ce scénario est loin d'être exceptionnel. Il illustre un biais systémique : les organisations investissent dans la couche applicative (les modèles, les plateformes) sans consolider la couche fondationnelle (les données elles-mêmes). C'est construire un gratte-ciel sur du sable.
Les 5 niveaux de maturité data vers l'IA
Les 4 erreurs les plus fréquentes en gouvernance des données
Observer les organisations dans leur parcours de transformation révèle des patterns récurrents. En voici quatre qui coûtent cher.
Erreur n°1 — Confondre gouvernance et RGPD
La conformité réglementaire est nécessaire, mais insuffisante. Une organisation peut être RGPD-conforme et avoir des données métier totalement inutilisables pour l'analytique. La gouvernance couvre un périmètre beaucoup plus large que la protection des données personnelles.
Erreur n°2 — Laisser la DSI seule au volant
La gouvernance des données est un sujet de gouvernance d'entreprise, pas uniquement de gouvernance IT. Si les métiers (finance, commercial, opérations) ne sont pas impliqués dans la définition des règles, les politiques resteront lettre morte. Le rôle de Data Steward — interface entre les équipes métier et data est souvent le maillon manquant.
Erreur n°3 — Vouloir tout gouverner d'un coup
L'approche "big bang" cartographier toutes les données de l'organisation avant de commencer, est une garantie d'enlisement. Les programmes qui réussissent adoptent une logique de valeur incrémentale : identifier les domaines de données à fort enjeu (clients, produits, transactions), les gouverner en priorité, mesurer les résultats, puis étendre.
Erreur n°4 — Négliger la dette technique des données
Comme la dette technique logicielle (sujet traité en détail ici), la dette des données s'accumule silencieusement : données dupliquées, schémas non documentés, pipelines sans monitoring. Plus elle grandit, plus elle devient coûteuse à résorber.

Par où commencer : un cadre en 4 étapes
La mise en place d'une gouvernance efficace n'exige pas de repartir de zéro. Elle demande de la méthode et une séquence réaliste.
Évaluer la maturité actuelle
Cartographier les principales sources de données, identifier les lacunes de qualité et les zones sans propriétaire défini.
Définir les domaines prioritaires
Cibler les données les plus critiques pour les décisions stratégiques, clients, produits, finances et concentrer les premiers efforts là.
Établir le modèle opérationnel
Nommer les Data Owners, créer les Data Stewards, établir les règles de qualité et déployer un catalogue de données accessible.
Mesurer et itérer
Définir des KPIs de qualité (taux de complétude, cohérence, fraîcheur) et revoir les politiques trimestriellement selon les résultats.
Ce cadre est délibérément simple. L'objectif n'est pas de produire un document de gouvernance exhaustif, mais de lancer une dynamique mesurable. Chaque organisation a sa propre maturité de départ, l'important est de progresser avec constance.
Pour aller plus loin sur la dimension SI et architecture, notre article sur comment structurer votre système d'information pour l'IA et la Data offre une perspective complémentaire sur l'architecture technique sous-jacente.
Le lien avec la stratégie IA
Une gouvernance des données solide n'est pas une fin en soi, c'est un accélérateur. Elle permet de :
Réduire le time-to-value des projets IA. Quand les données sont cataloguées, documentées et de qualité connue, les phases de préparation qui représentent en moyenne 60 à 80 % du temps d'un projet data science, se raccourcissent drastiquement. C'est directement corrélé au time-to-value des projets IT, un levier de performance souvent sous-estimé.
Garantir la confiance dans les décisions automatisées. Un modèle IA qui prend des décisions (priorisation des leads, prédiction des défauts, scoring de risque) doit être auditable. Sans traçabilité des données sources, l'audit est impossible et la confiance des métiers ne suit pas.
Préparer la conformité réglementaire à venir. L'AI Act européen impose des exigences croissantes de transparence et de documentation sur les données utilisées pour entraîner des systèmes d'IA. Les organisations qui auront investi dans leur gouvernance data seront structurellement mieux armées pour y répondre.
À retenir : Chaque euro investi en gouvernance des données génère un multiplicateur sur les investissements IA futurs. C'est l'un des rares chantiers IT dont le retour sur investissement s'améliore avec le temps parce que la qualité des données s'améliore en continu.
Conclusion
La gouvernance des données n'est pas glamour. Elle ne fait pas les manchettes comme les grands déploiements Copilot ou les projets d'IA générative. Pourtant, c'est elle qui détermine plus que tout autre facteur, si une organisation peut transformer ses données en avantage compétitif réel.
Les entreprises qui réussissent leur transformation data-IA partagent un point commun : elles ont traité la gouvernance comme une priorité stratégique, pas comme une tâche de maintenance. Elles ont nommé des responsables, défini des règles, mesuré des indicateurs. Et c'est sur cette fondation qu'elles ont construit des usages IA durables.
La question n'est plus "avez-vous une stratégie IA ?" mais "avez-vous les données pour la soutenir ?"
Références et ressources
- Gartner — AI Trends & Insights, 2025-2026
- IBM — The Cost of Poor Data Quality
- Microsoft — Microsoft Purview — Gouvernance des données unifiée
- Commission Européenne — AI Act — Cadre réglementaire européen sur l'IA
- DAMA International — DMBOK — Data Management Body of Knowledge
- Arrioph Blog — Structurer votre SI pour l'IA et la Data
- Arrioph Blog — Dette technique : le frein silencieux de votre transformation
- Arrioph Blog — Time-to-value : la métrique que vos projets IT ignorent